
Project archive · 2026-06-07
c-rusted-rs (a C-rusted inspired checker)
A C-rusted inspired toy static checker for C.
- C
- Rust
- Static Analysis
- Programming Languages
About c-rusted-rs
c-rusted-rs is available on GitHub at LucaCiucci/c-rusted-rs. The repository is currently archived, and I do not plan to develop it further.
c-rusted-rs was a short personal experiment: a toy Rust-written static checker for C, inspired by the C-rusted proposal. It is not complete, sound, or production-ready. Its purpose was to explore how quickly simple Rust-like annotations for C turn into real static-analysis infrastructure: CFGs, dataflow, points-to information, cached analyses, ownership-like checks, and simplified borrow checking.
What this project is about
C-rusted 12 proposes a restricted and annotated subset of C that aims to recover some Rust-like safety guarantees while remaining close to existing C code. c-rusted-rs3 is an experimental static checker written in Rust, implementing a small subset of the ideas described in the C-rusted abstract1.
The goal of this project was not to build a complete or production-grade C-rusted checker. Instead, I wanted to explore how some of the proposed checks could be implemented in practice, and how much static-analysis infrastructure would be needed before those checks started to compose naturally.
In particular, the prototype explores nominal types, ownership-like checks, borrow conflicts, custom state-property contracts, reusable dataflow analyses, and a small language-server integration.
Rationale and scope
Since the initial presentation of the idea45, no public implementation of C-rusted has been released, although the project has been presented multiple times at conferences456, and has attracted some interest from the Rust community7.
I was curious about what an implementation might look like, so I built this prototype as a personal experiment. The goals, roughly in order of importance, were:
- to have fun implementing a static checker for C in Rust;
- to explore the feasibility of some ideas from the C-rusted draft1;
- to learn, and sometimes accidentally reinvent, basic static-analysis techniques for C.
The non-goals were equally important. This project does not aim to:
- provide a complete implementation of the C-rusted checker;
- provide a production-grade static checker for C;
- handle the full C language;
- serve as a reference implementation of C-rusted;
- make any claim of soundness or completeness.
It is best understood as a small implementation story: starting from a public language proposal, I tried to build enough infrastructure to see which checks were straightforward, which ones required more semantic information, and where the hard parts would begin.
Hands-on
I approached c-rusted-rs as a small static-analysis tool built on top of libclang89, with a collection of Rust crates implementing the analysis logic, diagnostics, examples, and editor tooling.
Using libclang was a deliberate compromise. It exposes only a limited subset of Clang’s AST and API, but it was enough to build a prototype without having to interact with the full complexity of Clang internals. For a small proof of concept, that trade-off felt reasonable: I could parse real C code, inspect declarations and expressions, and focus most of the effort on the checker itself.
The downsides were also clear. libclang does not expose Clang’s CFG, nor any lower-level IR, which meant that anything requiring control-flow-sensitive reasoning would need additional infrastructure later on. Still, for the first experiments, the simplicity was worth it.
First approach: nominal types
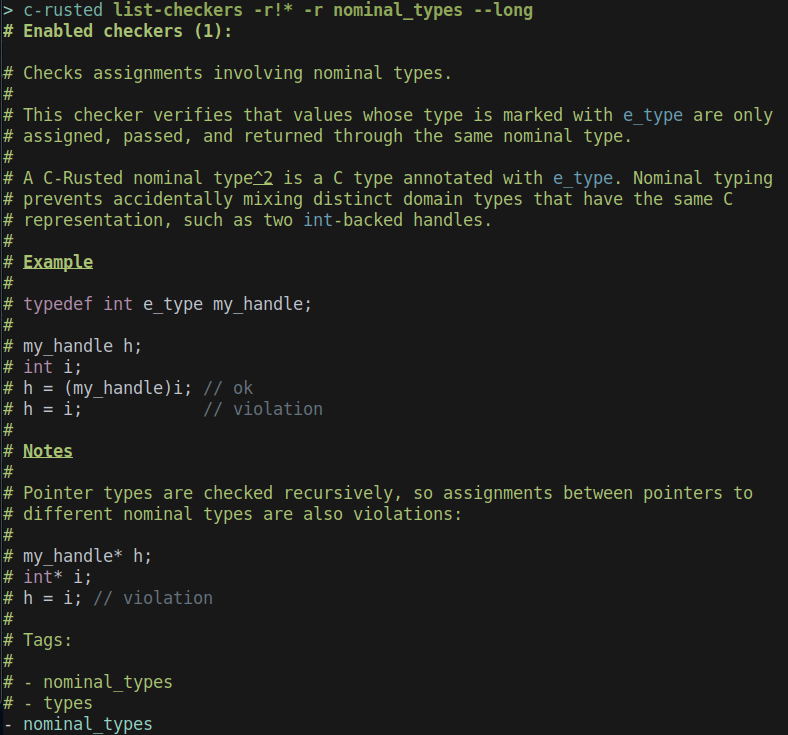
The first rule I implemented was nominal typing. It looked like the most direct part of the C-rusted proposal to prototype, and it gave me a useful way to get familiar with libclang.
The idea is to build a small nominal type system on top of C. A typedef can be marked with a special e_type annotation, and the checker then treats that typedef as a distinct nominal type, rather than simply as an alias of its underlying C type. Operations requiring type compatibility can then be checked against these nominal types.
The first step was to recognize the special e_type declarations. I considered two possible approaches:
- define macros that expand to nothing, then inspect the macro expansions;
- define
e_typeas a special attribute recognized by the checker, then inspect the AST for that attribute.
The first option would probably have been cleaner from the C side, but libclang does not expose enough macro-expansion information for this to be convenient. So I went with the second option: make e_type expand to a special Clang annotation attribute, and let the checker recover the semantic meaning from the AST.
In c-rusted-rs-examples/include/crusted/core.h, I defined:
#define e_annotate(a) __attribute__((annotate("crusted_" # a)))
#define e_annotate_with(a, ...) __attribute__((annotate("crusted_" # a, __VA_ARGS__)))This is simple enough to be recognized through the libclang API, while still leaving room for more complex annotations if needed.
The e_type annotation is then just a small wrapper around it, defined in c-rusted-rs-examples/include/crusted/nominal_types.h:
#define e_type e_annotate(type)The checker itself is fairly straightforward, and lives in crates/analyzer/src/checker/nominal_types.rs. It traverses the AST, looks at nodes such as VarDecl and BinaryOperator, and whenever it finds an operation that requires type compatibility, it compares the types of the operands. The comparison recursively follows pointers and typedefs, while preserving the additional nominal information introduced by e_type.
Over time, I built a small test suite in c-rusted-rs-examples/examples/nominal_types/. This does not implement every nominal-typing idea described in the C-rusted draft1. In particular, I ignored concepts such as bop, since they did not add much conceptual value to this prototype and would mostly have increased the amount of front-end bookkeeping.
Overall, nominal types were simple to implement, but they were a useful first checkpoint. They forced the project to parse annotations, report diagnostics, walk the AST, and compare enriched type information. At the same time, they were not yet very “static-analysis-heavy”: most of the logic was local and syntactic.
The more interesting parts started once the checks needed to reason about control flow.
CLI and reporting
Once the first checker was working, the project needed a command-line interface and a way to report diagnostics.
For the CLI, I used clap10, which is a standard and well-supported choice for Rust command-line tools. Over time, I integrated the CLI with the checker infrastructure so that checkers could register themselves together with their descriptions.
For this, I used a nice crate called markdown_to_ansi11, which made it possible to render markdown documentation directly from doc comments. With a small amount of glue code in crates/doc-comment-macros/, each checker could expose a short Markdown description that was then rendered nicely in the terminal.
For diagnostics, I used annotate-snippets12, the same crate used by the Rust compiler to render error messages. This gave the prototype readable reports with source snippets and annotations, without requiring a custom diagnostic-rendering system.
Annoying behavior of
One thing I found slightly surprising is that annotate-snippetsannotate-snippets can be unforgiving when the input spans are malformed. In some cases, feeding an invalid report causes a panic rather than a recoverable error. This is consistent with the general style of many compiler-internal APIs: if an invariant is broken, panic and get a stack trace. That makes sense for compiler development, but it can be a little frustrating while still figuring out how to build correct diagnostics.
Another issue was that annotate-snippets does not support ansi escape codes in the report annotations: it just breaks the rendering. This was not a big deal, but it’s unpleasant: I wanted to render inline markdown in the reports but I guess it’s just not possible without forking the crate and adding support for it.
CFG generation
Most of the remaining checks require some form of control-flow sensitivity. Nominal types can be checked mostly by looking at local AST nodes, but ownership-like rules, use-after-move checks, borrow conflicts, and state-property transitions all need to know how execution can flow through a function.
This is where the libclang approach started to show its limits. libclang exposes enough AST information for many local checks, but it does not expose Clang’s CFG, nor any lower-level IR. Since I still wanted to keep the project lightweight, I added a small CFG generator on top of the libclang AST.
The first version of this CFG generator was bootstrapped with AI assistance and then adapted to the needs of the prototype. It is far from complete: it only targets the subset of C I needed for the examples, and it inherits some limitations from libclang, especially around UnexposedExpr nodes. Still, it was enough to make the next layer of analyses possible.
A real implementation would probably not do this. It would use the full Clang API, or another proper C frontend, and reuse an existing CFG or IR instead of reconstructing one from the limited libclang view.
In this project, using a CFG directly had two practical advantages:
- it stayed close to the original program syntax, which made diagnostics easier to report because nodes could still be related naturally to source locations;
libclangdoes not expose a lower-level IR, so building analyses over SSA or another intermediate representation would not have been practical without switching frontend entirely.
With a CFG in place, the prototype was ready for more interesting checks.
Before implementing those checks, however, I needed one more layer of infrastructure: a small framework for dataflow analyses.
Early experiment: “leapfrog”, a badly named fixed-point solver
Some of the ideas introduced by C-rusted require more than local AST inspection. In particular, ownership-like checks, liveness information, and points-to reasoning all need to propagate information across the control-flow graph.
This was the point where Polonius1314 became a very useful reference for me. Polonius models borrow checking as a set of facts and rules over control-flow points. In its initial prototype, some of these rules were encoded explicitly and evaluated using Datafrog15, a Datalog-inspired engine. The loan analysis chapter is a good example of this style, and naive.rs shows one concrete implementation.
I liked the approach, but for this prototype I wanted something much smaller and more direct. My first idea was to represent the CFG as a graph with an abstract state attached to each point, then repeatedly propagate information along the graph until no state changed anymore.
In practice, each rule was a function that looked at a node and its neighboring states, produced a new state for that node, and pushed affected neighbors back into a worklist whenever something changed.
This is just a standard worklist-based fixed-point computation for dataflow analysis. At the time, however, I was mostly rediscovering the idea by building it, so I gave the first version a terrible name: “leapfrog”. The name was inspired by leapfrog integration16 in numerical analysis, although the two techniques have essentially nothing to do with each other.

Redesigning the dataflow solver
The first version worked, but it was too ad hoc. I later split it into a more generic and reusable fixed-point engine, now located in crates/analyzer/src/dataflow/.
The core abstraction is the DataflowProblem trait, defined in crates/analyzer/src/dataflow/problem.rs:
pub trait DataflowProblem {
type State: PartialEq;
type Error;
fn bottom(&mut self, cfg: &Cfg) -> Self::State;
fn compute(
&mut self,
cx: &mut Cx,
cfg: &Cfg,
from: &[(Point, &Self::State)],
p: (Point, &Self::State),
to: &[(Point, &Self::State)],
) -> Result<Self::State, Self::Error>;
}A DataflowProblem defines the abstract state associated with CFG points, the bottom state, and the rule used to recompute the state at a point from its neighborhood.
The fixed-point computation is handled by a worklist-driven solver in crates/analyzer/src/dataflow/solver.rs:62. The idea was to keep the solving strategy separate from the analysis definition: individual checkers should describe the analysis they need, while the solver takes care of repeatedly applying it until the states stabilize.
In practice, the simple worklist solver was enough for all the checkers I implemented, so I never needed to replace it with anything more sophisticated.
This particular trait definition drops the incoming edge type. Ideally, the edge information should have been preserved, but none of the implemented checkers needed it. I removed it to keep the prototype simple. If a later checker had required edge-sensitive behavior, I would have added it back.
Test bench: a toy only-one-call checker
To test the dataflow engine, I needed a small analysis that was easy to understand but still required control-flow reasoning. I invented a deliberately nonsense artificial rule to test the dataflow engine:
A function should be called at most once in a function body.
For example, this function is accepted because foo is called at most once along each execution path (c-rusted-rs-examples/examples/only_one_call/008_if_ok.c):
void f() {
if (1) {
foo();
} else {
foo();
}
}But this function is rejected because the loop can call foo more than once (c-rusted-rs-examples/examples/only_one_call/004_while.c):
void f(void) {
while (1) {
foo();
}
}This rule was intentionally simple, but it was useful as a test bench,
The propagation rule was small:
fn compute(
&mut self,
cx: &mut Cx<'tu>,
cfg: &Cfg<'tu>,
from: &[(Point, &Self::State)],
_p: (Point, &Self::State),
_to: &[(Point, &Self::State)],
) -> Result<Self::State, Self::Error> {
let mut state = self.bottom(cfg);
for (call, call_points) in from.iter().flat_map(|(_, s)| &s.previously_called_functions) {
for call_point in call_points {
state.previously_called_functions.entry(call.clone()).or_default().insert(*call_point);
}
}
for (from_point, _) in from {
if let Some((_ntt, _callee, usr)) = called_function(cx, cfg, from_point) {
state.previously_called_functions.entry(usr).or_default().insert(*from_point);
}
}
Ok(state)
}Then each node could be checked against the computed state:
fn check<'tu>(&self, cx: &mut Cx<'tu>, cfg: &Cfg<'tu>, point: &Point) {
let Some((call_ntt, callee_entity, callee_usr)) = called_function(cx, cfg, point) else {
// not a call, ok
return;
};
let Some(previous_calls) = self.previously_called_functions.get(&callee_usr) else {
// no previous call, ok
return;
};
// report violation
cx.push_report(Self::report_with_previous_calls(cfg, &call_ntt, &callee_entity, previous_calls));
}The full implementation is in crates/analyzer/src/checker/only_one_call.rs.
The checker itself is intentionally useless, but it served its purpose of testing the solver to express non-local properties with a small amount of checker-specific code.
Lattice-based dataflow analysis and domains
After implementing the first few analyses, I noticed that many of them had the same shape. They were forward analyses over the CFG, propagating an abstract state that approximated some property of the program.
In other words, they were small abstract interpretations of the function body.
So I introduced a second abstraction: a domain. In this prototype, a domain defines the abstract state of the analysis, a bottom element, a join operation for merging incoming states, and a transfer function for updating the state at each CFG point.
The trait, named LatticeAIDomain, looked like this:
pub trait LatticeAIDomain {
type State;
type Error;
fn bottom(&mut self, cfg: &Cfg) -> Self::State;
fn join(
&mut self,
cx: &mut Cx,
cfg: &Cfg,
incoming: &[(Point, &Self::State)],
) -> Result<Self::State, Self::Error>;
fn transfer(
&mut self,
cx: &mut Cx,
cfg: &Cfg,
p: Point,
old: &Self::State,
incoming: &Self::State,
) -> Result<Self::State, Self::Error>;
}This made the common structure explicit. The solver could handle the fixed-point mechanics, while each analysis only had to define:
- what information it tracks;
- different paths are joined;
- how each program point transforms the state.
A more complete lattice-based analysis framework would need more machinery (e.g. widening and narrowing to ensure convergence). For the checkers implemented in this prototype, however, the domains were small and simple enough that a simple join-based fixed-point computation was sufficient.
Adding widening or narrowing at this stage would not have made the prototype more useful. It would mostly have added complexity before there was a concrete analysis that needed it.
Analysis context and hooks
At this point, I needed one last core utility: an analysis context.
The context was passed through the analyses and provided three basic facilities:
- access to the AST;
- a way to emit reports;
- a storage area for arbitrary analysis data.
In the code, this appears as either AnalysisContext or Cx, and it is defined in crates/analyzer/src/analysis_context.rs.
That small interface turned out to be enough. Everything else could be built on top of it.
In particular, I introduced the concept of “hooks”. The name is not very accurate in hindsight: they are not hooks in the usual callback sense. They are simply traits that extend the analysis context with additional functionality while relying only on the core facilities listed above.
The most useful one was UseCached, which exposes a use_cached method. This made dependencies between analyses explicit and concise. For example, many checkers need to know the possible pointees of each pointer. With UseCached, the points-to analysis could be shared with one line:
let pto = cx.use_cached::<PtoAnalysis>(ntt)?;This runs the points-to analysis at most once for each function-like entity ntt, then reuses the cached result whenever another checker asks for it.
This was a small piece of infrastructure, but it had a large impact on the design. Instead of manually threading analysis results through the whole checker pipeline, each checker could request the information it needed, and the context would take care of computing and caching it.
Search for cx\..*\b in the repo to see more examples of how hooks are used in the checkers.
Testing
For this project, I used several forms of tests for the Rust code:
- unit tests for core utilities;
- integration tests for CFG generation, based on fixtures;
- integration tests for the checkers, implemented as golden tests.
For the checker tests, a redacted form of the emitted reports is saved and compared as YAML. For example, see c-rusted-rs-examples/examples/use_after_move/003_simple.c.reports.yaml.
Using a structured format for diagnostics also made it easy to experiment with other report outputs. One experiment was generating PDF reports for the examples, where diagnostic spans are rendered together with the relevant code snippets and annotations. See c-rusted-rs-examples/chimera.typ and c-rusted-rs-examples/examples/examples.typ.
The project is still heavily under-tested. It is a PoC, and the current test suite reflects that. However, I still consider the overall testing strategy reasonable: unit tests for isolated utilities, fixture-based tests for CFG construction, and golden tests for end-to-end checker behavior. This was actually very useful during development.
Recursion dangers
I did not expect recursion to become a major issue for the checkers I wanted to implement, and for a PoC this would not have been my biggest concern anyway. After all, even real compilers sometimes consider stack manipulation an acceptable mitigation when deeply recursive structures are unavoidable, as in rustc’s stack utilities.
Still, I tried to reduce unnecessary recursion where the code naturally allowed it.
One example is RecursiveEntityIterator, which provides an iterative way to walk Clang entities. For example:
for ntt in RecursiveEntityIterator::new(root.clone()).entities_only() {
// do something with ntt
}This pattern appears in several places in the repository, often through helper functions such as analyze_all_entities.
This was a useful step up from simple AST visitors. A traditional visitor-based traversal tends to make recursive code the default: you write the visitor, recurse into children. In this project, using explicit iterators made traversal behavior easier to control and reuse.
Towards real checkers: points-to and actions analysis
All the checkers described so far, except for nominal types, need some sensitivity to what the program actually does.
At this point, two questions became central:
- which relevant operations happen in the program?
- which memory locations may those operations affect?
The first question led to the actions analysis. The second one led to the points-to analysis.
Actions
The actions analysis is a small translation layer over the CFG. Its job is to extract the operations that are relevant for the later checkers.
In a cleaner implementation, this layer might not have been necessary: the checker could operate directly on a well-designed intermediate representation. In this project, however, I was working on top of libclang, and inspecting the exact meaning of expressions through its AST API can quickly become painful. Translating the relevant operations into a simpler internal representation made the rest of the project easier to write.
The implementation is in crates/analyzer/src/checker/actions.rs. I will not go into all the details here, because the idea is simple: the analysis emits a list of relevant actions, currently represented by this enum:
enum Action {
Move {
lhs: Vec<AccessPath>,
rhs_options: Vec<AccessPath>,
},
Use {
source: Vec<AccessPath>,
mode: UseMode,
},
}The points-to analysis
C is full of pointers. They are not completely different from Rust references: both are values that can refer to memory. The difference is that C pointers come with far fewer guarantees and far more freedom, so computing precise points-to information is much harder.
For this project, I wanted a useful over-approximation without falling into every rabbit hole of a real C pointer analysis. This was a PoC, so I accepted several important limitations:
- unions are not handled, because they would require especially careful modeling and access to details that
libclangdoes not expose; - some
UnexposedExprcases in the CFG are ignored; - possible aliasing between function arguments is ignored;
- no explicit lifetime model is implemented;
- global variables and uninitialized pointers are only approximated.
The third and fourth points are especially important. For example, in a function like this:
void f(int* a, int* b) {}the analysis assumes that a points to an abstract place *a, and that b points to a distinct abstract place *b. It does not try to infer that the caller may have passed two aliases of the same object.
This hits a very fundamental limitation of the C-rusted approach IMO. In Rust, the reference model ties mutability and aliasing together. As the RustBelt paper17 puts it, shared references are the dual of mutable references17. In other words, Rust’s borrowing model is not merely a mutability model; it is also an aliasing discipline.
In C, ordinary pointers do not carry such a discipline. A pointer of type int * does not say whether it is unique, shared, borrowed, owning, non-aliasing, or temporarily exclusive. It is just a pointer. In the absence of additional information, a sound checker has to conservatively assume that pointers may alias each other, potentially even when not compatible.
So this is a fundamental limitation of the currently proposed C-rusted approach: this makes ownership-like reasoning difficult to recover from C syntax alone. To obtain Rust-like guarantees, a C-rusted checker needs more than ownership annotations: it also needs a precise model of aliasing, lifetimes/regions, and function interfaces. At the time of writing, this part seems under-specified1. This, of course, doesn’t mean that the annotations can’t be deduced in some common cases like Rust does with implicit lifetime annotations.
In C there are some limited aliasing rules. For example for optimization reasons, the Type-Based Alias Analysis (TBAA) rules contains the following principle: “Two pointers of different types cannot alias each other, unless one of them is a character type.”1819.
This is a useful rule, but it is not enough to recover Rust-like guarantees. For example, if a and b have the same type, they could still alias each other, either directly or indirectly so this rule does not help at all in the general case and should not be relied on for a C-rusted specification or production-grade checker.
This is a real soundness limitation. However, modeling it properly would require the function interface to carry much richer information about aliasing, regions, ownership, and lifetimes. At that point, the project would start turning into a much more complete Rust-like borrow-checking model for C, which was far beyond the scope of this prototype.
The same limitation appears with return values and modified arguments. The only practical analysis mode for this kind of C-rusted checker, at least in my opinion, is intra-procedural analysis driven by function contracts. Without those contracts, a call such as this:
int* g(int*, int*);
void f(int* a, int* b) {
int* c = g(a, b);
}has to be approximated somehow. In this prototype, c is assumed to point to a fresh abstract place. This is not sound in general: g could have returned a, b, a global object, or something else. But handling that correctly would require function summaries or annotations describing the relationship between arguments, return values, and reachable memory. This is the exact kind of limitation that the note above describes.
Global variables are similarly simplified. I modeled them mostly like ordinary variables. That is acceptable for a small prototype, but only up to a point. A production implementation would either need to treat global state conservatively, require annotations, or become inter-procedural.
Atoms, places, and access paths
The implementation started with the idea of defining a few primitive concepts, somewhat inspired by the way Polonius models borrow-checking facts. In practice, crates/analyzer/src/checker/points_to/atoms.rs ended up containing types that are not exactly “atoms”, but the name remained.
The most important concept is Place.
Places
After a few design iterations, a Place in c-rusted-rs became similar to Rust’s Place in MIR.
Side by side, the two shapes are roughly:
// c-rusted-rs: | rustc_middle:
// ----------------------------------------------------------
struct Place { // struct Place {
base: PlaceBase, // local: Local,
projection: Projection, // projection: &List<PlaceElem>,
} // }
struct Projection(SmallVec<[ProjectionComponent; 4]>);The important difference is the base. In rustc_middle, a place is rooted in a Local, that is, a MIR local variable. In c-rusted-rs, the base is more generally an abstract memory allocation:
enum PlaceBase {
Source(SourceId),
Nullptr,
}This difference comes from a different treatment of dereferences.
In c-rusted-rs, projections are limited to fields and array indexing:
enum ProjectionComponent {
Field(Field),
Index,
}In rustc_middle, by contrast, dereference is itself a projection element:
enum ProjectionElem<V, T> {
Deref, // <- !!!
Field(FieldIdx, T),
Index(V),
}That Deref variant hides the key design difference.
In MIR, a place is always rooted in a local variable, and dereferences can appear inside the projection. In c-rusted-rs, a Place represents a precise abstract memory location. Dereferencing belongs to a different level of abstraction.
Access paths
Dereferences are represented by access paths:
pub enum AccessPath {
Base(PlaceBase),
Projection(Vec<AccessPath>, ProjectionComponent),
Deref(Vec<AccessPath>),
Ref(Vec<AccessPath>),
}So an AccessPath in this project is conceptually different from a MIR Place.
A Place represents an abstract memory location. An AccessPath represents a sequence of operations used to reach a memory location.
For example, x.field and *p are access paths. The job of the points-to analysis is to resolve those paths into sets of possible places.
Points-to sets
The points-to analysis needs a way to represent a mapping from pointer places to possible pointee places.
The obvious representation would be something like:
HashMap<Place, HashSet<Place>>However, that becomes awkward when dealing with projections. For example, if we know something about x, x.field, and x.field[i], it is useful for the data structure to reflect that hierarchy.
For this reason, I represented the store as a tree:
struct PlaceStore<LeafData> {
roots: BTreeMap<PlaceBase, PlaceTree<LeafData>>,
}
enum PlaceTree<LeafData> {
/// Non-initialized tree node.
Deferred,
StructNode {
fields: BTreeMap<Field, PlaceTree<LeafData>>,
},
ArrayNode {
element: Box<PlaceTree<LeafData>>,
},
LeafNode {
data: LeafData,
},
}The implementation is in crates/analyzer/src/checker/points_to/store.rs.
The LeafData parameter represents the information associated with each place. For the points-to analysis, this is simply a set of possible pointees:
type PlaceSet = BTreeSet<Place>;So the points-to store is essentially a PlaceStore<PlaceSet>.
A few design notes:
ArrayNodeis deliberately imprecise: all array elements are merged into a single abstract element — this is a very useful over-approximation an yet it could easily be swapped and improved if needed;- unions are not modeled;
- the
Deferredvariant was useful, but it also introduced some annoying edge cases.
Points-to implementation
The goal of the points-to analysis is:
Given an access path, resolve it to the set of possible places it may denote.
Once the representation is in place, the abstract interpretation part is conceptually straightforward, although the implementation is somewhat verbose. The current implementation is in crates/analyzer/src/checker/points_to/problem.rs.
The main complication is that some updates are intentionally imprecise. For example, when assigning through an array path, the analysis cannot know which concrete element is affected. Therefore, it does not overwrite the old information; it merges the new information into the previous abstract state.
This is conservative with respect to the abstraction used by the prototype, but it also means that precision can degrade quickly when indexing is involved.
Termination and the need for a less precise analysis
After implementing this, I realized that the analysis was more precise than the later checkers actually needed.
For example, a diagnostic usually does not need to recursively resolve a pointer to a very specific abstract memory location. Rust borrow-checker diagnostics typically say that *p is involved; they do not try to explain the entire resolved pointee tree.
There was also a deeper issue: resolving through pointers in this way can create unbounded abstract structures. A fully robust version of this analysis would need a widening step to guarantee termination in the presence of recursive or repeatedly extended structures.
In hindsight, a better design for this project would have been a more semantic and less aggressively resolving points-to analysis. Instead of always chasing through pointers to produce the most precise place set possible, the analysis could have stopped at expressions such as *p and treated them as meaningful abstract locations in their own right.
That would probably have been simpler, more stable, and better aligned with the needs of the checkers. However, changing the computation at that point would have required some refactor, and the existing implementation was good enough for the goals of the PoC.
Adding widening would not have been especially difficult from an infrastructure point of view: the framework could track some history and add a widen method to the LatticeAIDomain trait. However, this was not the main limitation of the prototype. The more important soundness boundaries were already elsewhere: function summaries, argument aliasing, explicit lifetimes, globals, unions, and the incomplete C model. For that reason, I decided not to spend more time making the points-to analysis more complete than the rest of the project.
A simple but non-trivial checker: custom properties
One idea presented in the C-rusted draft1 is the concept of custom properties. These are a way to attach semantic metadata to a resource and then check that function contracts are respected.
For example:
void mixer_open(Mixer_t * e_out("door", "opened") mxp);
void mixer_on(Mixer_t * e_in("door", "closed") e_out("blade", "on") mxp);
void f(Mixer_t *mxp) {
mixer_open(mxp);
mixer_on(mxp); // <- contract violation
}This example is simple, but it is also the first point where the pieces built so far start to come together.
I defined a CustomPropertiesAnalysis, whose job is to propagate custom properties over the CFG. The analysis implements LatticeAIDomain, so the propagation rules are expressed as a fixed-point computation over a lattice. The abstract state is a PropertiesState at each CFG point.
This checker needs both the actions analysis and the points-to analysis, so it requests them through the analysis context:
let actions_analysis = cx.use_cached::<ActionsAnalysis>(ntt)?;
let points_to_analysis = cx.use_cached::<PtoAnalysis>(ntt)?;Both analyses implement Cacheable, so they are computed at most once for each function-like entity and then reused by all checkers that need them. This is where UseCached starts to pay off: the custom-properties checker can depend on other analyses without manually coordinating the whole analysis pipeline.
The implementation is in crates/analyzer/src/checker/custom_properties.rs.
Once the dependencies are available, a DataflowSolver solves the CustomPropertiesAnalysis over the CFG. The resulting solution is then inspected to report contract violations.
The code is a little verbose, but the core compatibility check is small:
fn is_compatible(
current: Option<&MaybeKnown<BTreeSet<String>>>,
required: &BTreeSet<String>,
) -> bool {
let Some(Known(current)) = current else {
return required.is_empty();
};
for current in current {
if !required.contains(current) {
return false;
}
}
true
}The meaning is: if the current property set is unknown, then only an empty requirement can be accepted. Otherwise, every currently known property must be allowed by the contract.
A very similar checker is use_after_move. It follows the same general structure, but the abstract state is simpler: the only relevant non-bottom state is essentially “moved”. Another checker, invalid_move, adds extra checks to reject invalid ownership transfers, such as trying to take ownership of a local variable through a pointer.
The important part is not that any of these checkers is individually complicated. The important part is that, once actions, points-to information, cached analyses, and the dataflow solver exist, adding new checkers becomes mostly a matter of defining the right abstract state and the right contract checks.
A non-forward propagation checker: loan analysis and the “borrow checker”
The loan checker is the interesting exception to the previous pattern.
Most of the checkers described so far can be expressed as forward propagation problems: walk through the CFG, update the abstract state, join states at merge points, and report violations when the state is incompatible with the operation being analyzed.
Borrow checking needs something slightly different.
To know whether a loan is still relevant, the checker needs to know whether the corresponding loan is used later. In other words, liveness matters. A loan should not necessarily remain live until the end of the lexical scope: it remains relevant while later uses can still observe it. This is closer to Rust’s non-lexical lifetime intuition than to a simple lexical-scope check.
For that reason, the loan analysis is not expressed as a simple LatticeAIDomain forward propagation checker. Instead, it computes which loans are live at each CFG point. In this sense, it is bidirectional and has to implement DataflowProblem directly. The borrow checker can then be written as a small pass over that result.
The high-level structure of crates/analyzer/src/checker/borrow.rs is surprisingly compact:
let analysis = cx.use_cached::<LoanAnalysis>(ntt)?;
report_violations(cx, ntt, &analysis.cfg, &analysis.solution);- looks for borrows issued at that point;
- reads the set of live loans from the loan-analysis solution;
- groups the new borrows by the place being borrowed;
- compares the new borrows with older live loans for the same place;
- emits diagnostics when the Rust-like borrowing rules are violated.
The two rules are the familiar ones:
- a new exclusive borrow conflicts with any other live borrow of the same place, shared or exclusive;
- a new shared borrow conflicts with any live exclusive borrow of the same place.
In code, the core shape is:
fn report_violations(...) {
for p in cfg.points() {
// -- snip --
// Find borrows issued at this CFG point.
// Read the set of loans that are live here.
// Group new borrows by the place being borrowed.
// -- snip --
for (borrowed, new_loan_ids) in &by_borrowed {
// A mutable borrow conflicts with any other live borrow
// of the same place, shared or exclusive.
if !new_exclusive.is_empty() && !other_live.is_empty() {
emit_exclusive_borrow_conflict(...);
}
// An immutable borrow conflicts with any live mutable borrow
// of the same place.
if !new_shared.is_empty() && !live_exclusive.is_empty() {
emit_shared_borrow_conflict(...);
}
}
}
}The real implementation also builds diagnostics that point both to the new invalid borrow and to the previous live borrow that caused the conflict. This is an important part of making the checker understandable: the error should not only say that a borrow is invalid, but also explain which earlier borrow is still live.
This checker is still a simplified borrow checker, and it inherits the limitations of the points-to and aliasing model discussed earlier. However, it was one of the most satisfying pieces of the project: once the loan analysis existed, the borrow checker itself became almost declarative. It just stated the conflict rules.
Other checkers and scope boundaries
The prototype did not try to cover the full C-rusted annotation language.
This was intentionally narrower in scope. After implementing nominal types, custom properties, ownership-like moves, use-after-move checks, invalid moves, and a simplified borrow checker, the main goal of the project had already been reached: I had enough pieces to understand what kind of infrastructure a C-rusted-like checker would need.
Several parts of the original design remained out of scope but I consider the prototype useful despite its limitations. The goal was not to implement the full C-rusted language.
Optionality
I did not implement optional types.
In principle, optionality is one of the most natural checks to add: an optional pointer such as T * e_opt() should not be dereferenced or passed where a non-optional pointer is expected unless the optional value has been ruled out.
This would require adding back edge types and track the conditions, which is not pleasant given the libclang limitations.
Nominal operations and value constraints
The prototype implements basic nominal typing through e_type, but it does not implement the operation-level annotations such as e_bop(lhs, op, rhs) and e_uop(op, rhs).
I decided these were also out of scope and a pure technical exercise.
Safe and unsafe boundaries
I also did not implement the safe/unsafe boundary annotations.
This is mostly a matter of policy and interface checking once the underlying analyses exist. But it means that there should be a precise specification of what and unsafe boundary would do: just saying “unsafe code can do anything” is not specified enough.
For this prototype, I focused on the analyses themselves rather than on the boundary and exception mechanism around them.
Chimera
The repository contains a small “chimera” example: a concise showcase that combines several of the implemented c-rusted-rs checks in a single C file.
/*
c-rusted-rs chimera.
Compact showcase for the main checks currently implemented by the prototype
(e.g.nominal typing, custom state properties, borrowing, and ownership/move
rules).
*/
#include "./include/crusted.h"
// ================================================================
// API demo
// ================================================================
int atoi(const char *str);
typedef int e_type Mixer_t;
typedef Mixer_t *hMixer_t;
e_uninit() e_own Mixer_t *alloc_mixer(int id);
void mixer_ctor(
e_init()
e_out("cable", "detached")
e_out("blade", "?")
e_out("door", "?")
hMixer_t mxp
);
void mixer_attach_cable(
e_initialized()
e_in("blade", "off")
e_out("cable", "attached")
hMixer_t mxp
);
void mixer_detach_cable(
e_initialized()
e_in("blade", "off")
e_out("cable", "detached")
hMixer_t mxp
);
void mixer_on(
e_initialized()
e_in("cable", "attached")
e_in("door", "closed")
e_out("blade", "on")
hMixer_t mxp
);
void mixer_off(
e_initialized()
e_out("blade", "off")
hMixer_t mxp
);
void mixer_open(
e_initialized()
e_in("blade", "off")
e_out("door", "open")
hMixer_t mxp
);
void mixer_close(
e_initialized()
e_out("door", "closed")
hMixer_t mxp
);
void mixer_destroy(hMixer_t e_own mxp);
void inspect_mixer(const Mixer_t *mxp);
void service_mixer(Mixer_t *mxp);
// ================================================================
// Showcase
// ================================================================
e_uninit() e_own Mixer_t *alloc_mixer(int id) {
if (id == 0) {
// violation: `Mixer_t *` is nominally distinct from `int *`
return (int *)0;
}
return (Mixer_t *)42;
}
void mixer_on(
e_initialized()
e_in("cable", "attached")
e_in("door", "closed")
e_out("blade", "on")
hMixer_t mxp
) {
// A concrete implementation can use `e_set_property` to tell the checker
// that the postcondition has been established.
e_set_property("blade", "on", mxp);
}
void get_ready(
e_initialized()
e_out("blade", "off")
e_out("door", "closed")
e_out("cable", "attached")
hMixer_t mxp
) {
mixer_off(mxp);
mixer_attach_cable(mxp);
mixer_close(mxp);
}
void ok_blend_cycle(hMixer_t e_uninitialized() mxp) {
mixer_ctor(mxp);
get_ready(mxp);
mixer_on(mxp);
mixer_off(mxp);
mixer_open(mxp);
mixer_detach_cable(mxp);
}
void ok_allocated_cycle(int id) {
hMixer_t e_own mxp = alloc_mixer(id);
ok_blend_cycle(mxp);
}
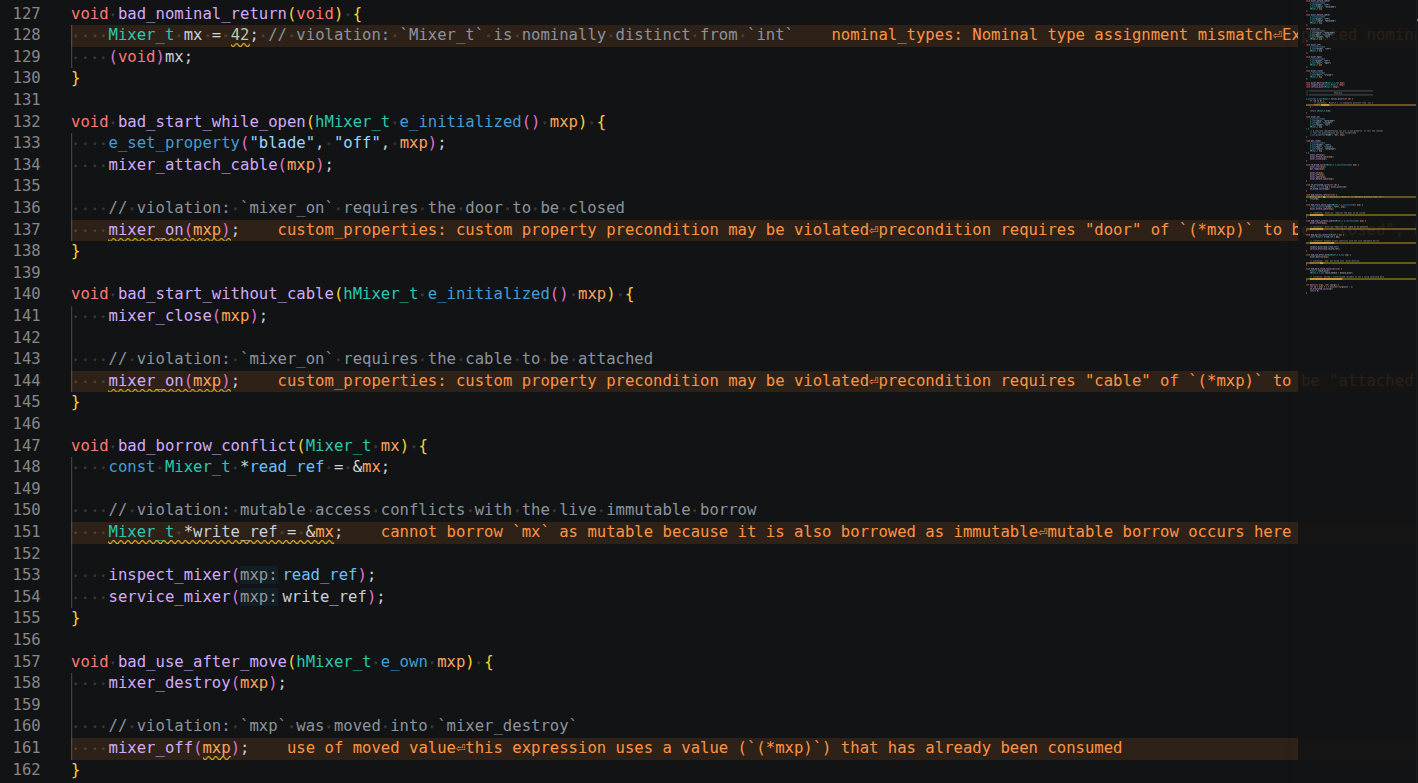
void bad_nominal_return(void) {
Mixer_t mx = 42; // violation: `Mixer_t` is nominally distinct from `int`
(void)mx;
}
void bad_start_while_open(hMixer_t e_initialized() mxp) {
e_set_property("blade", "off", mxp);
mixer_attach_cable(mxp);
// violation: `mixer_on` requires the door to be closed
mixer_on(mxp);
}
void bad_start_without_cable(hMixer_t e_initialized() mxp) {
mixer_close(mxp);
// violation: `mixer_on` requires the cable to be attached
mixer_on(mxp);
}
void bad_borrow_conflict(Mixer_t mx) {
const Mixer_t *read_ref = &mx;
// violation: mutable access conflicts with the live immutable borrow
Mixer_t *write_ref = &mx;
inspect_mixer(read_ref);
service_mixer(write_ref);
}
void bad_use_after_move(hMixer_t e_own mxp) {
mixer_destroy(mxp);
// violation: `mxp` was moved into `mixer_destroy`
mixer_off(mxp);
}
void bad_move_stack_resource(void) {
Mixer_t stack_mixer;
hMixer_t e_own stack_handle = &stack_mixer;
// violation: moving a stack-backed variable is not a valid ownership move
mixer_destroy(stack_handle);
}
int main(int argc, char **argv) {
int id = argc > 1 ? atoi(argv[1]) : 1;
ok_allocated_cycle(id);
return 0;
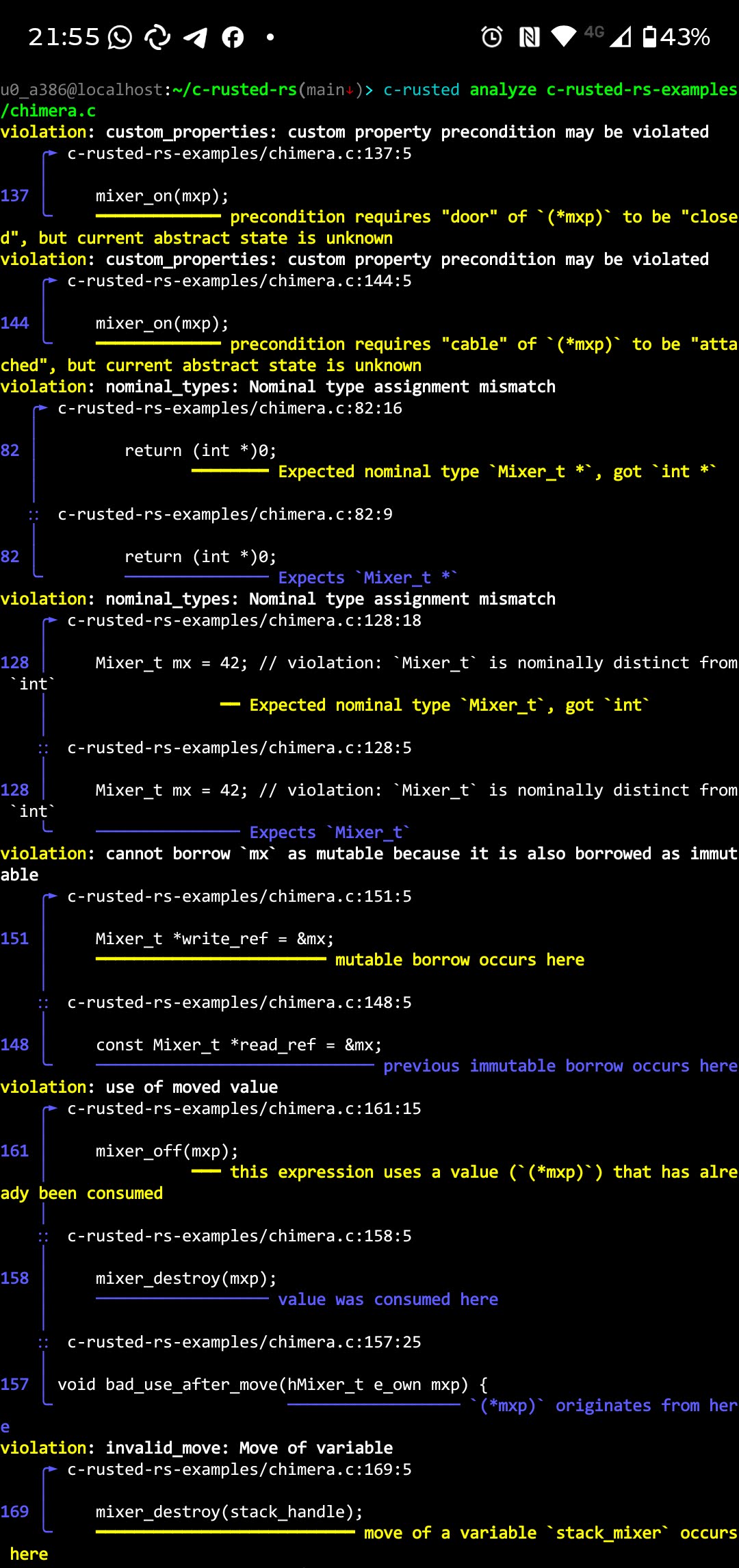
}The corresponding reports are shown below:
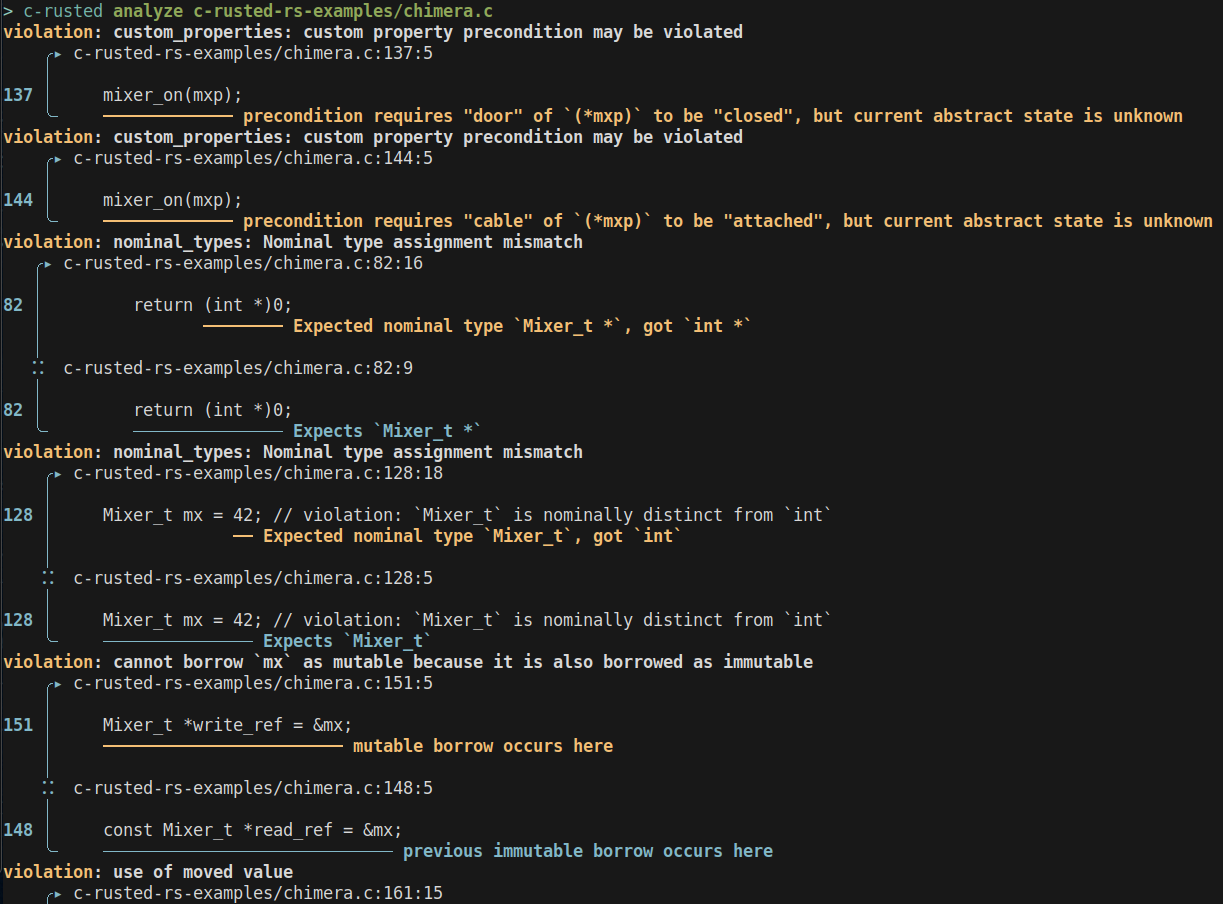
violation: custom_properties: custom property precondition may be violated
╭▸ c-rusted-rs-examples/chimera.c:137:5
│
137 │ mixer_on(mxp);
╰╴ ━━━━━━━━━━━━━ precondition requires "door" of `(*mxp)` to be "closed", but current abstract state is unknown
violation: custom_properties: custom property precondition may be violated
╭▸ c-rusted-rs-examples/chimera.c:144:5
│
144 │ mixer_on(mxp);
╰╴ ━━━━━━━━━━━━━ precondition requires "cable" of `(*mxp)` to be "attached", but current abstract state is unknown
violation: nominal_types: Nominal type assignment mismatch
╭▸ c-rusted-rs-examples/chimera.c:82:16
│
82 │ return (int *)0;
│ ━━━━━━━━ Expected nominal type `Mixer_t *`, got `int *`
│
⸬ c-rusted-rs-examples/chimera.c:82:9
│
82 │ return (int *)0;
╰╴ ─────────────── Expects `Mixer_t *`
violation: nominal_types: Nominal type assignment mismatch
╭▸ c-rusted-rs-examples/chimera.c:128:18
│
128 │ Mixer_t mx = 42; // violation: `Mixer_t` is nominally distinct from `int`
│ ━━ Expected nominal type `Mixer_t`, got `int`
│
⸬ c-rusted-rs-examples/chimera.c:128:5
│
128 │ Mixer_t mx = 42; // violation: `Mixer_t` is nominally distinct from `int`
╰╴ ─────────────── Expects `Mixer_t`
violation: cannot borrow `mx` as mutable because it is also borrowed as immutable
╭▸ c-rusted-rs-examples/chimera.c:151:5
│
151 │ Mixer_t *write_ref = &mx;
│ ━━━━━━━━━━━━━━━━━━━━━━━━ mutable borrow occurs here
│
⸬ c-rusted-rs-examples/chimera.c:148:5
│
148 │ const Mixer_t *read_ref = &mx;
╰╴ ───────────────────────────── previous immutable borrow occurs here
violation: use of moved value
╭▸ c-rusted-rs-examples/chimera.c:161:15
│
161 │ mixer_off(mxp);
│ ━━━ this expression uses a value (`(*mxp)`) that has already been consumed
│
⸬ c-rusted-rs-examples/chimera.c:158:5
│
158 │ mixer_destroy(mxp);
│ ────────────────── value was consumed here
│
⸬ c-rusted-rs-examples/chimera.c:157:25
│
157 │ void bad_use_after_move(hMixer_t e_own mxp) {
╰╴ ────────────────── `(*mxp)` originates from here
violation: invalid_move: Move of variable
╭▸ c-rusted-rs-examples/chimera.c:169:5
│
169 │ mixer_destroy(stack_handle);
╰╴ ━━━━━━━━━━━━━━━━━━━━━━━━━━━ move of a variable `stack_mixer` occurs hereLSP and VSCode extension
At this point, the CLI was already producing diagnostics in a structured and flexible format; see crates/reports/src/report.rs. I also had a small LSP prototype from a previous experiment.
That made adding editor integration relatively straightforward. The LSP implementation is in crates/cli/src/lsp.rs and mostly adapts the existing CLI reporting pipeline to the Language Server Protocol.
This was not one of the core goals of the project, but it was a useful validation of the report format. Once diagnostics are structured properly, they can be rendered in different places: terminal output, golden tests, generated reports, or an editor.
Profiling
For tracing, I used the tracing crate20. Together with tracing-profile21, this made it possible to export traces and inspect them in Perfetto22.
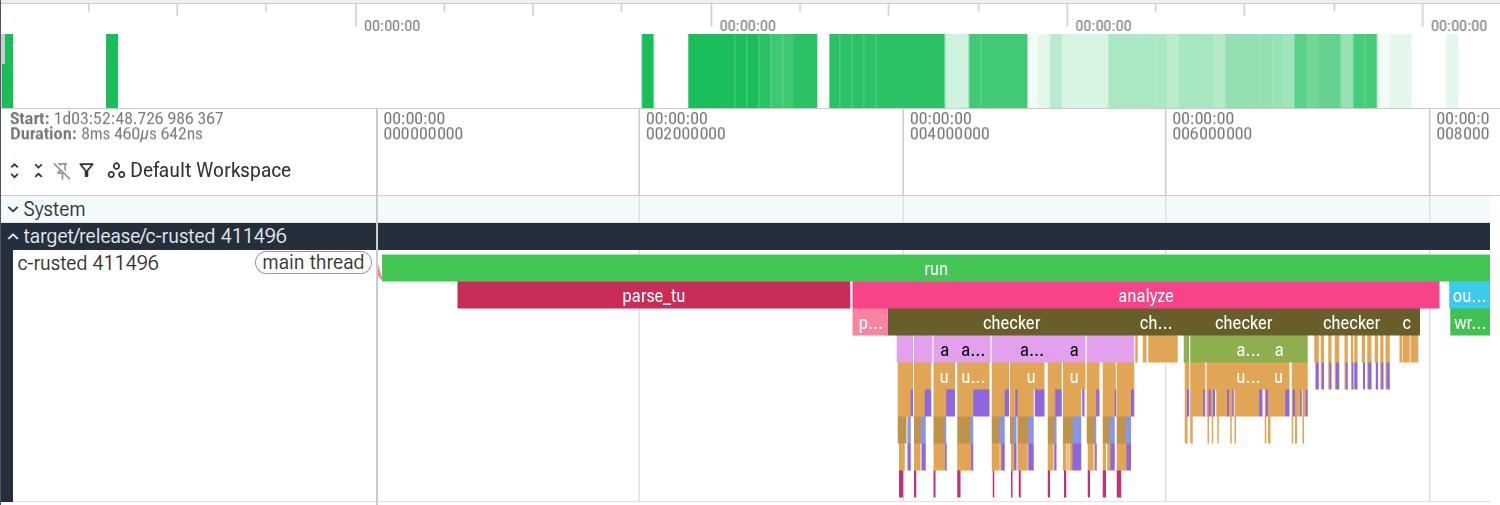
c-rusted-rs on the chimera.c example. In this general view, there are three main stages: parsing the C file with Clang, running the analyses and checkers, and finally printing the reports.
Zooming into a checker gives a very clean picture of the analysis pipeline. For example:
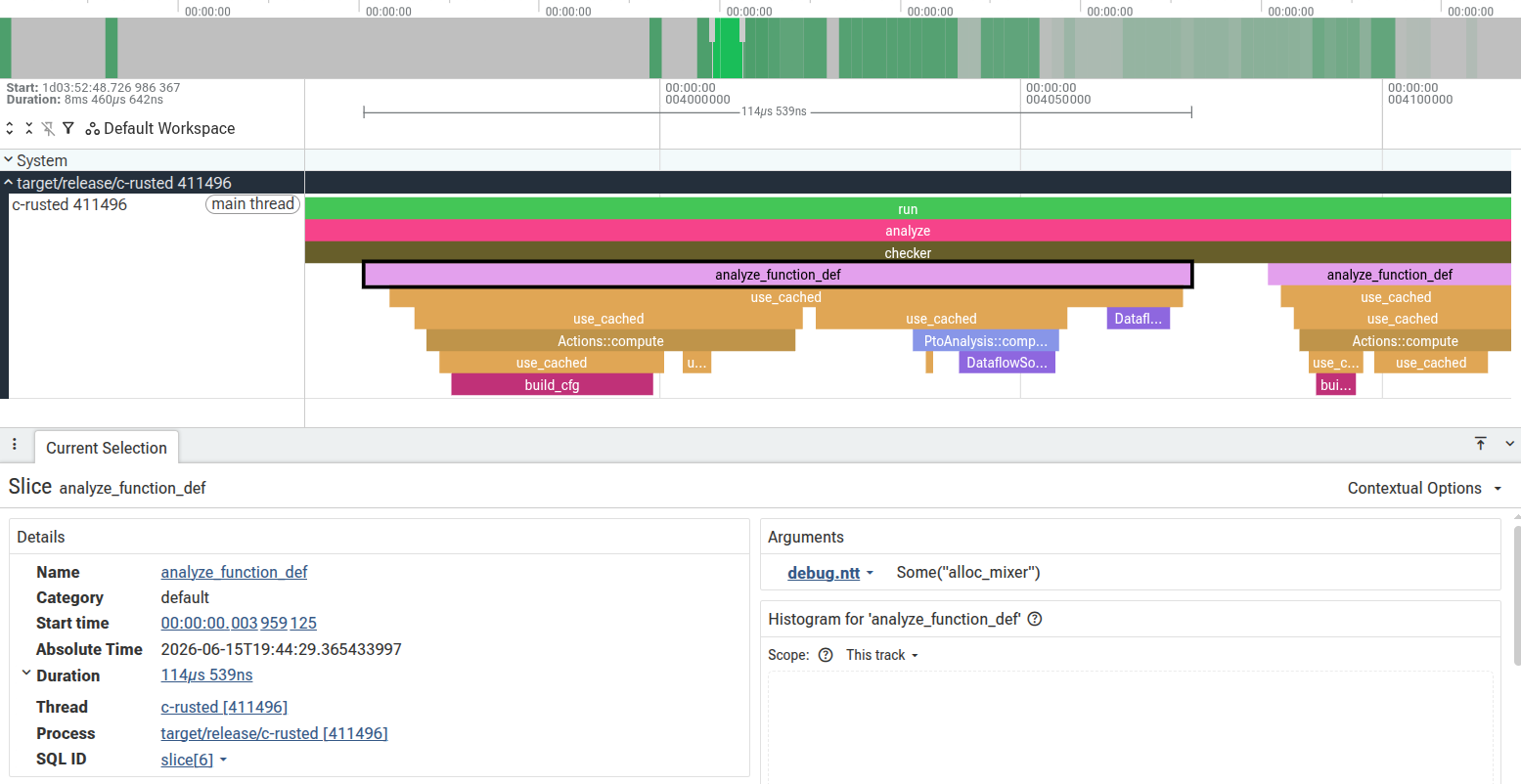
custom_properties checker on the alloc_mixer function. The checker first requests the actions analysis, which triggers CFG construction, then runs the PtoAnalysis, and finally solves the custom-properties dataflow problem.
I think this is useful less for performance tuning and more for understanding the execution structure of the analyzer. The traces make analysis dependencies visible: which checker requested which cached analysis, when the CFG was built, and where the dataflow solvers were spending time.
But can it run on my potato?
Of course.
c-rusted-rs running on my Android phone.
Conclusions
This project started from a question:
What would it actually take to implement a small part of a C-rusted-like checker?
The answer was: more infrastructure than the surface notation initially suggests.
Nominal types were easy to prototype. They mostly required parsing annotations, and enriching type information while walking the AST. But the moment the checks needed to reason about ownership, moves, borrows, or custom resource states, local AST inspection was no longer enough.
At that point, the project naturally grew several layers:
- a small CFG generator;
- a worklist-based dataflow solver;
- a lattice-oriented abstraction for forward analyses;
- an analysis context with cached dependencies;
- an actions analysis to translate relevant C operations into a simpler internal language;
- a points-to analysis to approximate which abstract places an operation may affect;
- higher-level checkers for custom properties, use-after-move, invalid moves, and borrow conflicts.
This was the most valuable part of the experiment. The individual checkers were not the hard part in isolation. The interesting part was discovering the intermediate analyses that made those checkers composable.
The project also made the limitations of this approach much clearer to me.
A C-rusted-like checker cannot recover Rust-like guarantees from C syntax alone. Rust’s reference model ties aliasing and mutability together: shared references may alias but cannot mutate, while mutable references may mutate but require exclusivity. Ordinary C pointers do not carry that discipline. Without additional information, compatible pointers may alias, function calls may return or store references in ways that are invisible to an intraprocedural checker, and global state can break local reasoning.
This means that a serious C-rusted checker needs more than ownership annotations. It needs a precise model for aliasing, lifetimes or regions, function contracts, unsafe boundaries, and probably a much stronger C frontend than the one used in this prototype.
So c-rusted-rs should not be read as an implementation of C-rusted, nor as a production static analyzer. It is better understood as an implementation diary: a small experiment that pushed the idea far enough to reveal the shape of the required machinery.
In that sense, I consider the project successful: it produced a working prototype, but more importantly, it turned a vague question into a concrete map of the design space: which checks are mostly syntactic, which ones are ordinary dataflow problems, which ones need points-to information, and which ones run into the deeper mismatch between Rust’s borrowing discipline and C’s pointer model.
The repository is archived, but the experiment did what I wanted it to do: it made the problem concrete.
Footnotes
-
https://www.bugseng.com/join-bugseng-at-embedded-world-2024/ ↩ ↩2
-
“C-rusted: a safe, secure and energy-efficient dialect of C”, https://www.youtube.com/watch?v=Pk2RAl8kG1o ↩
-
https://www.reddit.com/r/rust/comments/116y6v1/crusted_the_advantages_of_rust_in_c_without_the/ ↩